 2024/09/10 19:04
2024/09/10 19:04
How do the top 1 new games on the best-selling list make players addicted? Production team: Let the AI play 1 billion times first
2024/09/10 19:04
Translated by Optical Flow
At this year's CEDEC Developer Conference in Japan, QualiArts, the developer of "School Idol Master" (hereinafter referred to as Xuemeis), and CyberAgent, the parent company of QualiArts, shared their application examples of AI technology in the direction of game balance optimization.
In the previous sharing, we talked about the 3D technology and detail polishing of Xuemaus, if 3D technology is not suitable for all games, then the AI technology we are going to talk about today is more universal.
The gameplay of Learning from Mars is relatively unique, and its system framework is similar to the development mode of "Horse Racing Girl", but in each specific development link, Learning from Mars has added a mode called training course, which is actually card building (DBG).

The magic of DBG gameplay has been well known since "Slaying the Spire" became popular, and the micro-innovative gameplay of Learning from Mars naturally fascinates fans and players. Of course, from a development point of view, as an online game that needs to be updated for a long time, it is necessary to constantly add new cards in the basic DBG process, so the balance adjustment of cards will face rapid growth and long-term pressure.
Therefore, with the help of deep reinforcement learning, the Xuemaas project team has developed two sets of card game AI, as well as a balance adjustment support system, to solve the balance problem after adding new cards to the game.

Left: Takaya Ihara, Research Engineer, AI Strategy Headquarters, CyberAgent's Game and Entertainment Division; Right: Yuya Nasu, QualiArts.
Specifically, "Difficulties in Balance Adjustment".
Players need to build a deck first, and in the course gameplay of the development link, they draw cards from the card mountain and play them, and the effect of the cards will also change depending on the situation.
Therefore, depending on the card combination, even if there is a so-called balance-disrupting card in the deck, it will be difficult for the development team to find it accurately through human labor.

The production team's response was to use gray box optimization technology to generate a "deck exploration AI" that can find the strongest decks in a large combination, and a "curriculum AI" that could be used to try various games using deep reinforcement learning technology. When the two work together, the corresponding problems can be solved.

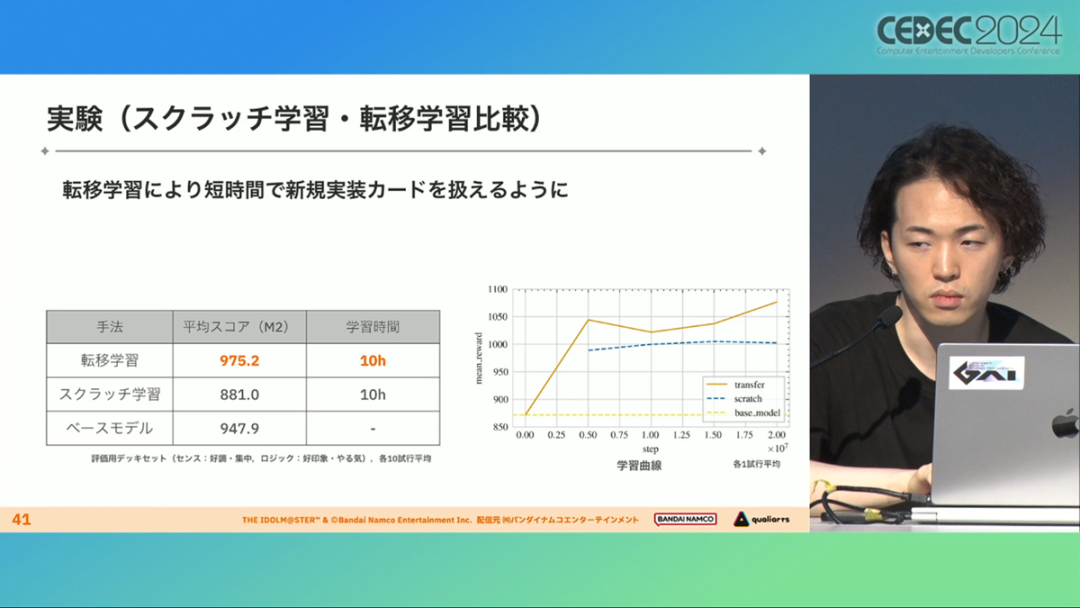
Since Learnmath has to think about long-term operations, it is also a challenge to add new cards in the short term. After all, if the AI learns more than 10 days in the workflow of installing a new card every month, it will not even be able to save time for verification after the balance adjustment.
Therefore, the production team tried a method of transferring the appended data to the specified learning model. This method is far more efficient than repeating "learning from scratch", reducing the learning process from more than 10 days to 10 hours. At the same time, it led to the creation of a "balance adjustment support system that allows planners to complete simulations".

Among them, QualiArts is responsible for developing in-game logic and building web applications/infrastructure for the balance adjustment support system, while CyberAgent is responsible for developing deck exploration AI and curriculum AI.

01
What is a Balance Adjustment Support System?
As mentioned above, Catcher AI only uses the model created from scratch when it is first generated, and then performs transfer learning when the master data is added. After that, the AI will build a deck around the newly added cards, and after repeated simulations and confirmation of the results, the new cards will be officially released if there are no problems.

Regarding de novo learning and transfer learning, the game can be roughly separated according to the character attributes "meaning" and "logic".
These consoles in the following diagram manage the metadata, and the actual model is saved in the W&B (Developer Collaboration Platform). There are no input parameters, which is typical of machine learning and is easy to use even without supporting knowledge.

The core logic of learning to execute is implemented in the Unity repository, and the design and implementation are also compatible in the . .NET runtime. As a result, the AI course implemented in Python can be played (learned) through socket communication.

The problem with managing AI models and performing learning in this way is that it is difficult for developers to understand what the model has learned, and it is difficult to understand the strength (i.e., reliability) of the model itself.

To solve the previous problem, you need to show the difference in the effect of the skill cards and items for the new learning objective before learning. The latter problem is solved by comparing it with the "Method for Producing Higher Scores with Certainty" (MCTS).
By the way, all of the card effect descriptions for the Learnmes cards are automatically generated based on the relevant master data, so that their differences can be detected dynamically.

The "Deck Discovery" feature in the workflow uses a serverless architecture centered on Google Cloud's Cloud Run/Batch.

This architecture enables parallel execution and allows for the flexibility to rescale when needed.

In addition, deck information and course AI play logs are stored and can be synchronized using spreadsheet data connectors. This allows game planners to manipulate and analyze data at will using the spreadsheets they're used to.

Through the above techniques, the project team achieved the following results:
By running the above system before the game goes live, it is possible to simulate more than 100 million decks before launch, and the cumulative number of course trainings exceeds 1 billion. If a real person were to try to achieve this result, it would take about 1900 years to achieve it, even if it only took one minute at a time.
Through so many simulations, the team was able to spot details that they didn't notice when designing or testing the game, which helped a lot with balance adjustments.
Specific examples include "Preventing Top Players' Decks from Becoming Similar" and "Preventing Skill Card Combinations from Looping". In addition, a derivative benefit is that this technology can also help detect game bugs.

02
Training in "Curriculum AI".
The project team's requirements for "Curriculum AI" are as follows:
1. Any card can be played under any circumstances;
2. The duration of each game is less than 0.1 seconds;
3. The time from adding a new card to confirming the result is less than 36 hours.
In other words, AI needs to aim for maximum efficiency and speed, learn within 36 hours of changing the master data, and generate easy-to-understand simulation results.

Learn the game of Mars course, which can be modeled as a Markov decision process (MDP). This model will accurately determine the next "state" based on the current "state" and "action".
By combining the above model with the Monte Carlo Tree Method (MCTS) game tree search method, we can continuously approach more accurate optimal behavior. By the way, the principle behind it is the same as a computer reading a move of shogi or Go.


But the problem with the above method is that the calculation time is long, and the average time consumed to execute a course with 9 rounds is 1416.2 seconds.
As a solution, the team adopted a scheme that aims to use "deep reinforcement learning" to approximate the optimal game behavior. In short, it's about letting the AI experience situations and learn through trial and error.

As a result, the AI obtained by the production team can play a score equivalent to that of MCTS, and the time to play a game can be controlled within 0.1 seconds. As shown in the figure below, although the average score is slightly lower, the average game duration meets the requirement of 0.1 seconds, which is equivalent to using AI to test more than 14,000 times the game in the same time.

In addition, in the case of the operation of constantly adding new cards, the production team had to solve the problem of learning time for the course AI. That's because, to achieve these levels of performance, AI would need to play at least 300 million times, which equates to 300 hours.

However, as the number of new cards continues to increase, this mechanism will reach its upper limit, so the production team uses text embeddings in large-scale language models (LLMs, supposedly using OpenAI's Embeddings API) to express state.
By using card effect text instead of in-game structure data, the system can ignore changes in the shape of the product's graphics and has the advantage of introducing new cards without additional learning.

As a result, the transfer learning mentioned above can be completed in a shorter period of time, and a more accurate game process can be obtained than using the de novo learning mode in the same amount of time.
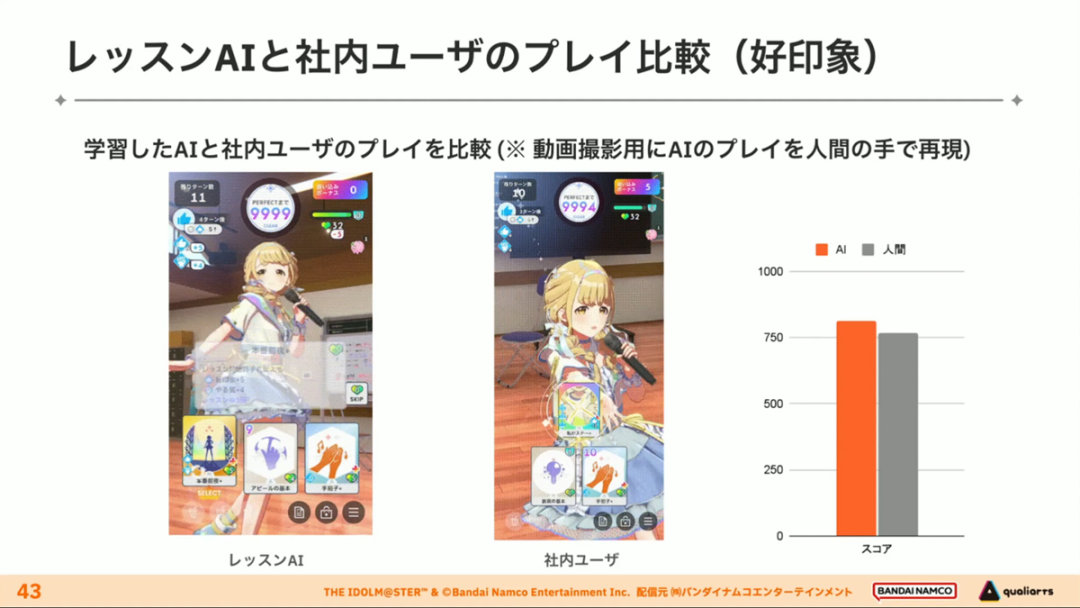
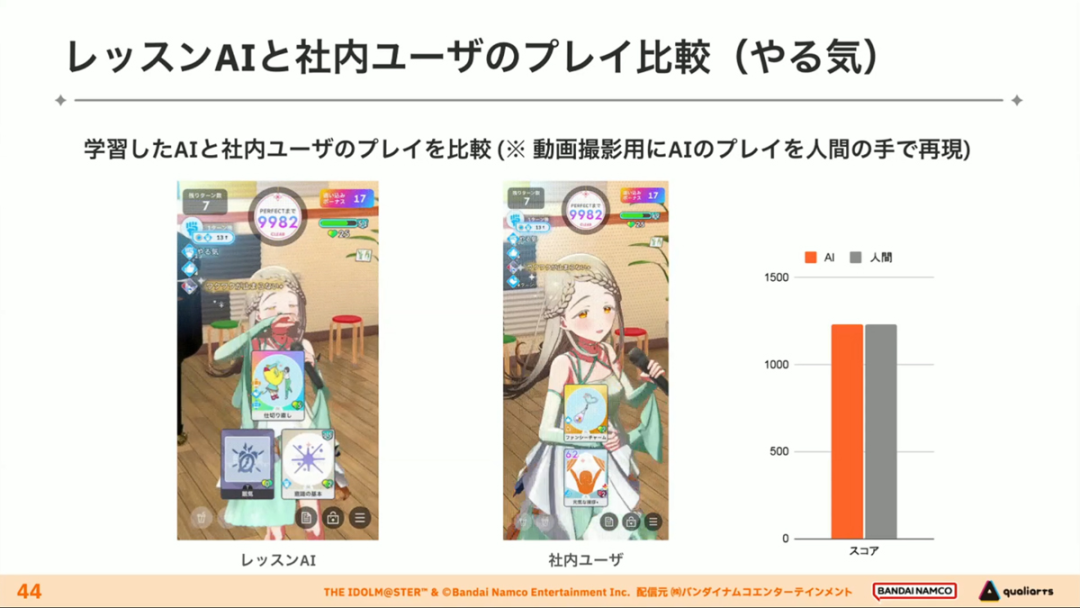
The course AI trained in the above way is not inferior to humans, or even very close to humans, when playing games.
Even when compared to the members of the production team who are familiar with Learn, the course AI can sometimes outscore these players in terms of scores, and even if the difference in playing style is only one move, the difference is very significant.
03
Deck building AI for LLM applications
The purpose of developing the "Deck Building AI" is to discover the decks with the highest scores that can disrupt the balance of the game. The production team believes that when the AI scores extremely high, it tends to be associated with cards or decks that are too strong.
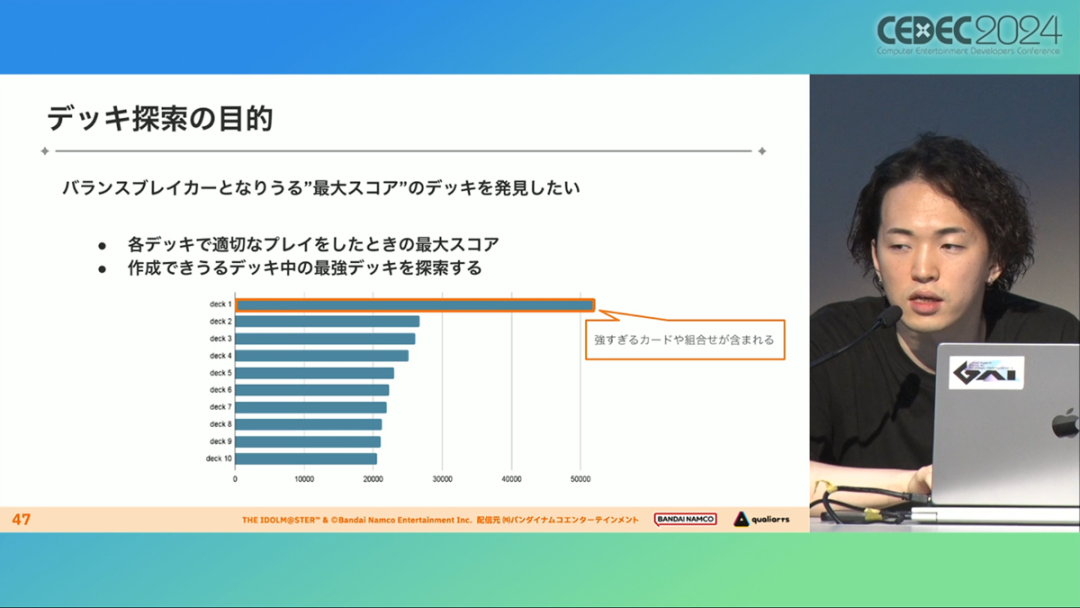
Even if you count the cards and items when the game was first launched, the number of combinations is huge (more than 10 to the 20th power), and it is impractical to recalculate and check it every time it is updated.
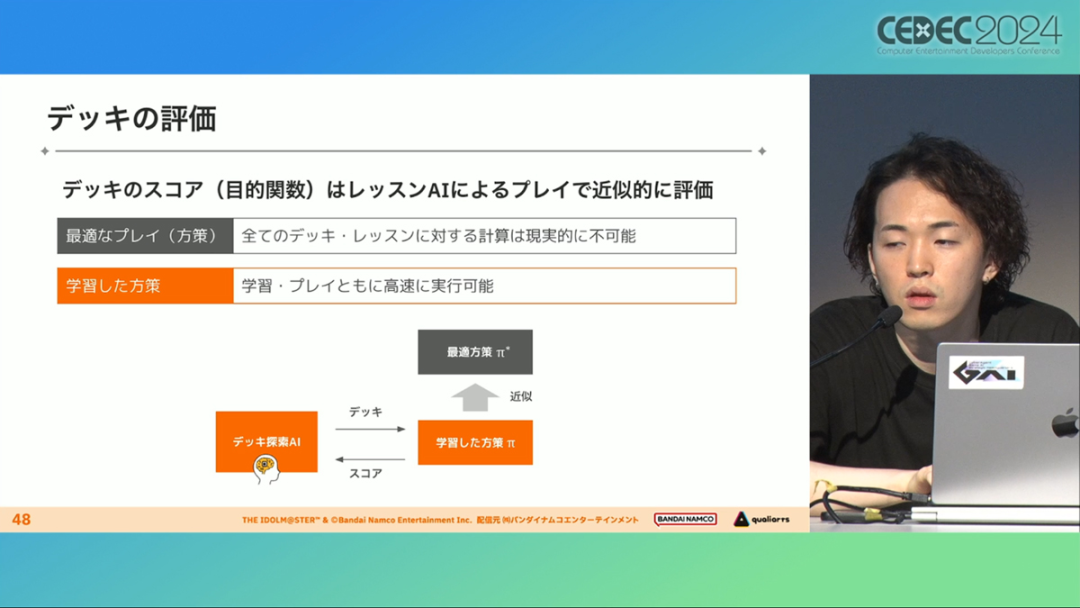
Therefore, instead of using the "black box optimization" technique to solve the problem using brute force, the production team adopted the "gray box optimization" technique associated with the problem part. In addition, text embedding using LLMs is used here.


The deck exploration algorithm uses genetic algorithms. This algorithm mechanism will combine two decks to generate a child deck, then evaluate the high decomposition method, and then continue to combine the excellent solutions to generate the next generation, and find (approximate) the best solution by causing sudden changes.

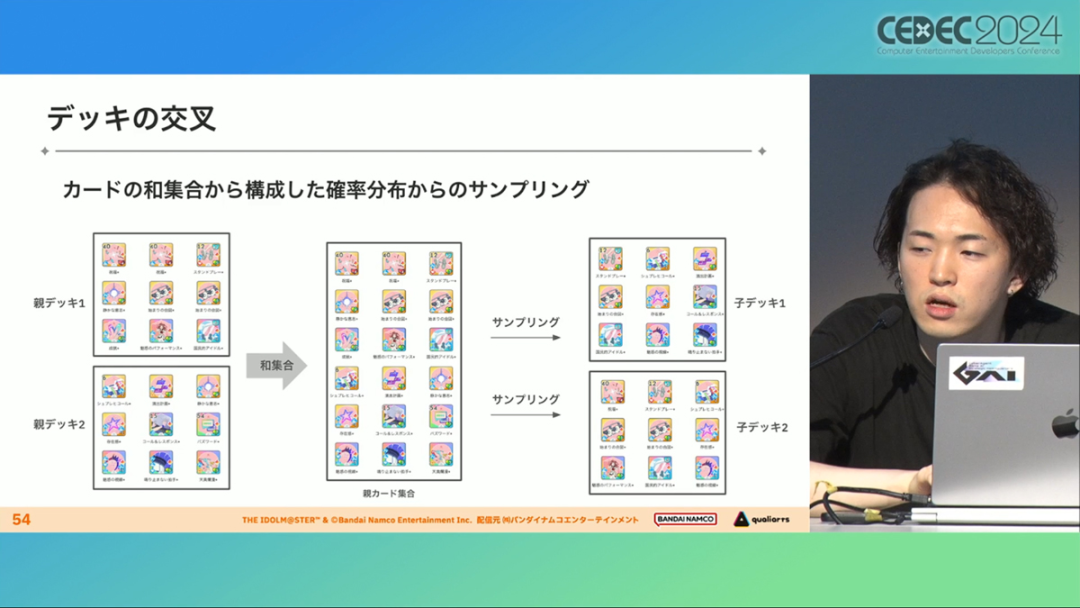
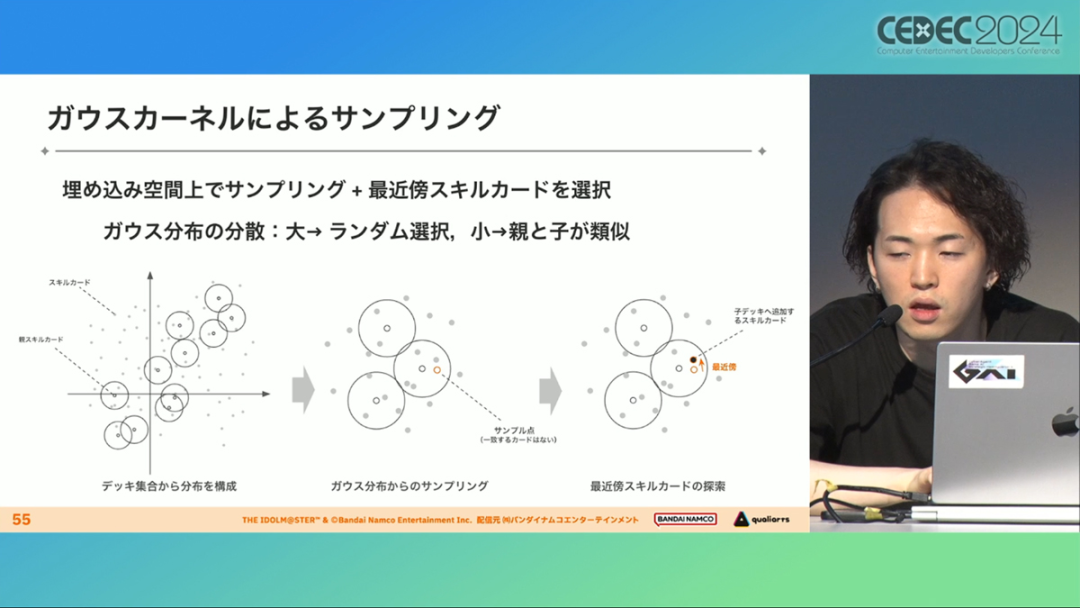
This algorithm is generally used as a framework for black-box optimization, but this time it is implemented as a gray-box optimization algorithm by introducing LLM vectorized card information.
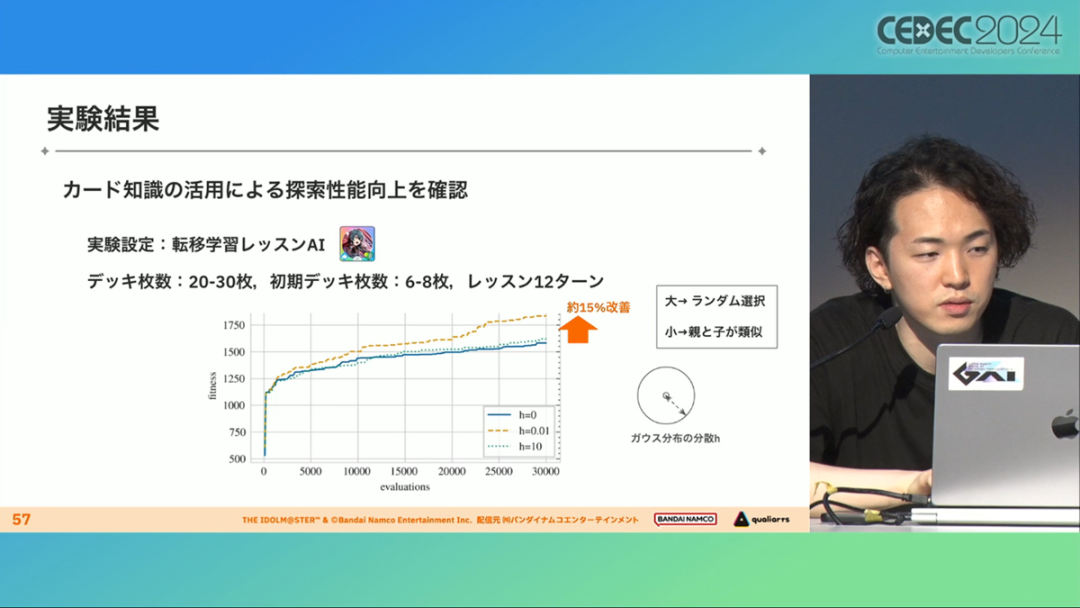
Specifically, we build a functional distribution in the deck set, sample points from the Gaussian distribution, and then look for cards near the points with empty spaces, and then add the cards to the deck. If the variance is large, the result is close to random selection, and if the variance is small, the result is that the parent offspring are similar.
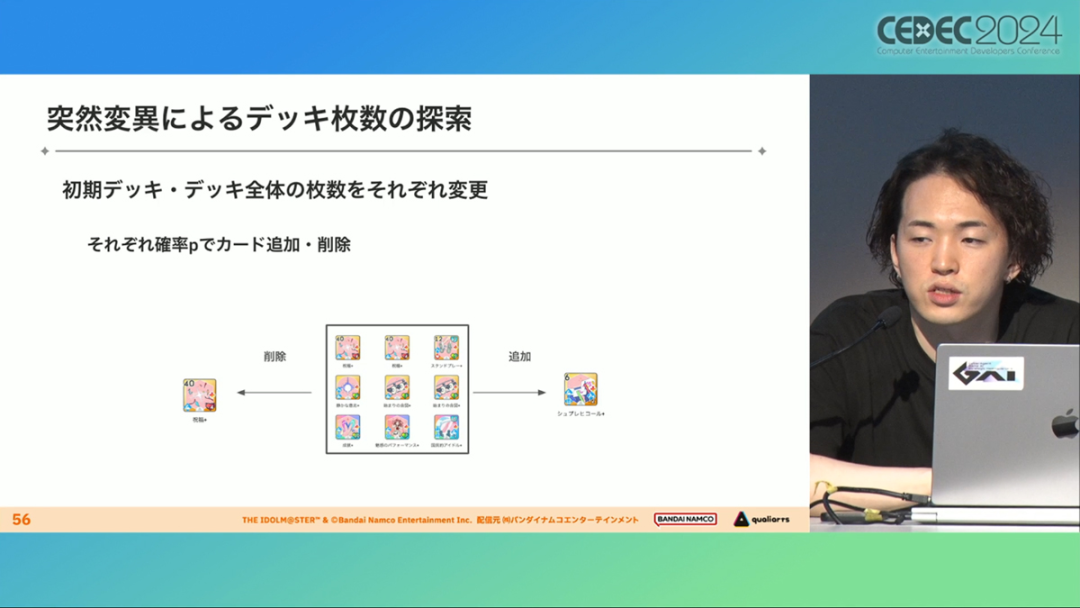
The results of the above attempts are as follows:
When a transfer-learning AI performs deck exploration, the total number of cards in the deck is set to 20~30 cards, the player's initial deck size is 6~8 cards, and the course is played for 12 rounds, and it can be seen that the efficiency of the results generated is about 15% higher than that of the complete random sampling algorithm.
By using these balance adjustment support systems, Xuemas has simulated more than 100 million decks and 1 billion lessons since the service began. The benefit to the project team is that many decks and genres that cannot be taken care of by manpower are adjusted and optimized.

Nowadays, the application of AI in most games is still in the aspect of AIGC generation resources, and we can see from the case of learning from Mars that AI is also of great help for game optimization testing and balance adjustment.
Regardless of the industry's previous assertion that "AI will eliminate 99% of practitioners", at least for the time being, mastering more AI technology can indeed help us improve R&D efficiency and optimize the quality of games.
This article is from Xinzhi self-media and does not represent the views and positions of Business Xinzhi.If there is any suspicion of infringement, please contact the administrator of the Business News Platform.Contact: system@shangyexinzhi.com